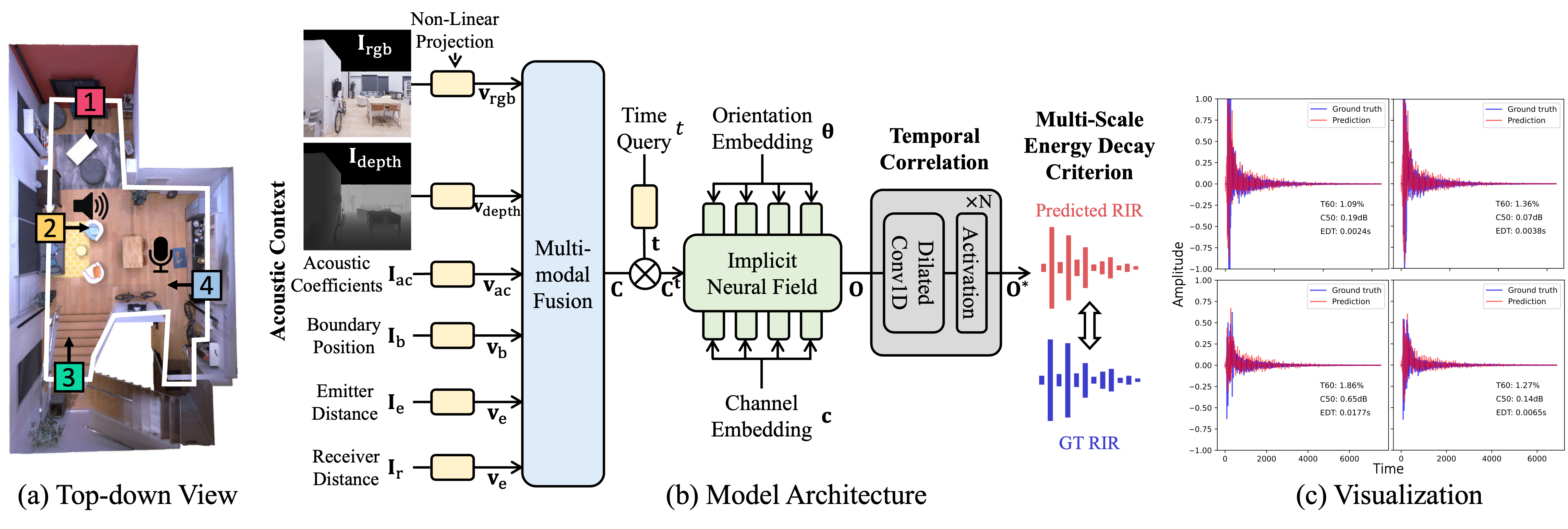
Method overview. The left (a) is the top-down view of an example indoor scene. We sample points evenly along the room boundary and extract various contextual information at each point, such as the RGB image, depth image, the acoustic coefficients of the surface, and several spatial information. The middle (b) is the architecture of our NACF model. First, we feed multiple acoustic contexts extracted along the room boundary (a) into the multi-modal fusion module. Then we integrate the fused contextual information with the time query as the spatial-temporal query, which is the input to the implicit neural field. After the neural field generates the RIR, we utilize a temporal correlation module to refine the RIR. Finally, we adopt the multi-scale energy decay criterion to supervise the model training. The right (c) is the visualization of predicted and ground-truth RIR together with generation errors.