In this paper, we introduce a novel task called language-guided audio-visual editing. Given an audio and image pair of a sounding event, this task aims at generating new audio-visual content by editing the given sounding event conditioned on the language guidance. For instance, we can alter the background environment of a sounding object while keeping its appearance unchanged, or we can add new sounds contextualized to the visual content. To address this task, we propose a new diffusion-based framework for audio-visual editing and introduce two key ideas. Firstly, we propose a one-shot adaptation approach to tailor generative diffusion models for audio-visual content editing. With as few as one audio-visual sample, we jointly transfer the audio and vision diffusion models to the target domain. After fine-tuning, our model enables consistent generation of this audio-visual sample. Secondly, we introduce a cross-modal semantic enhancement approach. We observe that when using language as content editing guidance, the vision branch may overlook editing requirements. This phenomenon, termed catastrophic neglect, hampers audio-visual alignment during content editing. We therefore enhance semantic consistency between language and vision to mitigate this issue. Extensive experiments validate the effectiveness of our method in language-based audio-visual editing and highlight its superiority over several baseline approaches.

Our framework for language-guided audio-visual editing. During training, we extract unimodal information from the audio-visual sample using pretrained encoders. Then, we fuse audio and visual features with an MLP and feed the output along with the text prompt into the text encoder. The text encoder generates textual conditions to guide the audio-visual diffusion model. We update the parameters of the MLP and diffusion models. During inference, we freeze all parameters of our model. We replace the training prompt with an editing prompt, e.g., we append "beside a crackling fireplace" to the training prompt "a telephone is raining." We inject the cross-model semantic enhancement module into the vision branch to improve semantic consistency. The generated audio and image accurately reflect the editing requirements.
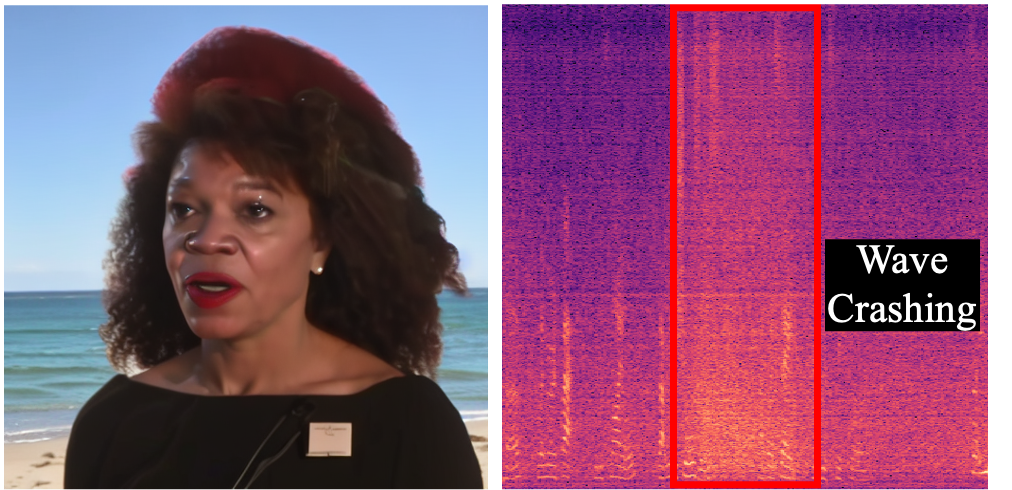
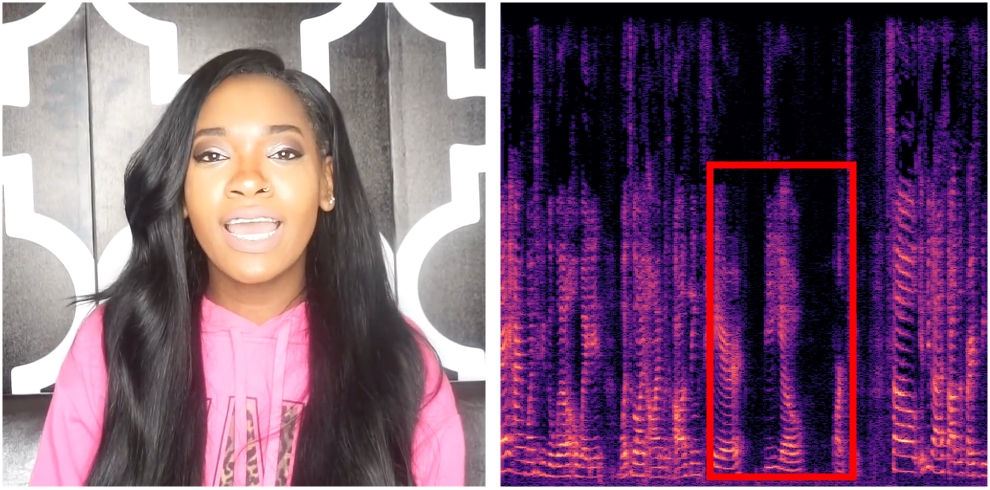
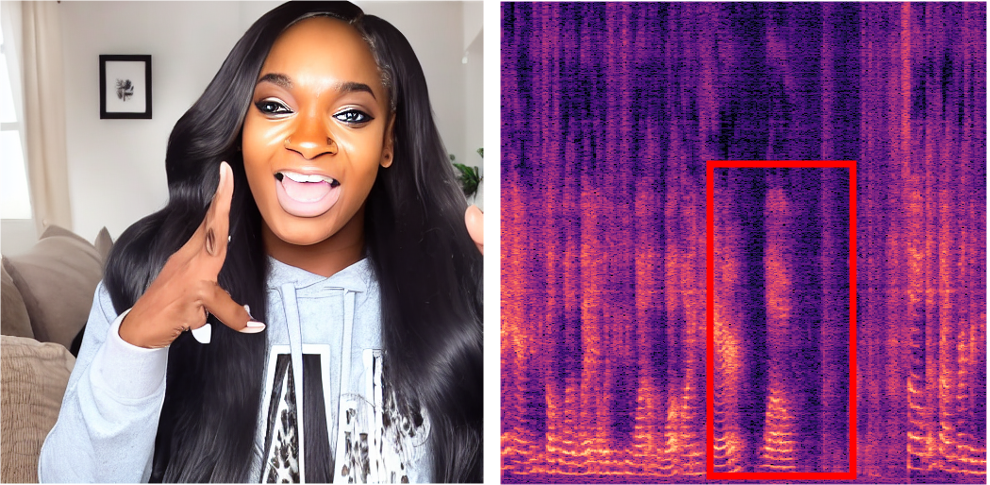
Below, you will find audio-visual content synthesized by our language-guided audio-visual editing model. For each example, we present the audio-visual data used for multimodal one-shot adaptation, the generated audio-visual data, and the editing prompts. For each audio clip, we convert waveform audio to spectrograms for better visual perception. Please prepare your headphone 🎧 or loudspeaker 🔈.
🌟 Audio-Visual Editing
We present some general audio-visual editing results, where we use language to guide the creation of audio-visual content.
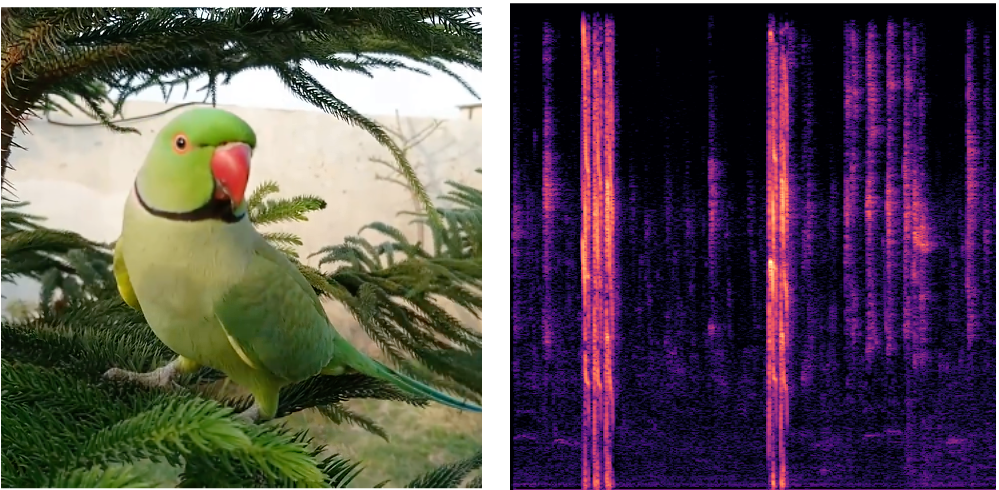
"A bird is chirping"
(Input Audio-Visual Data)
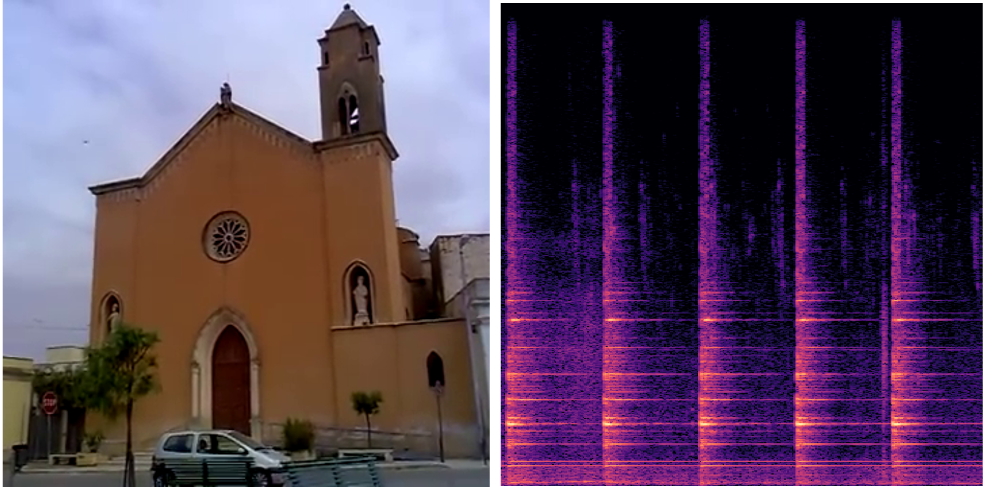
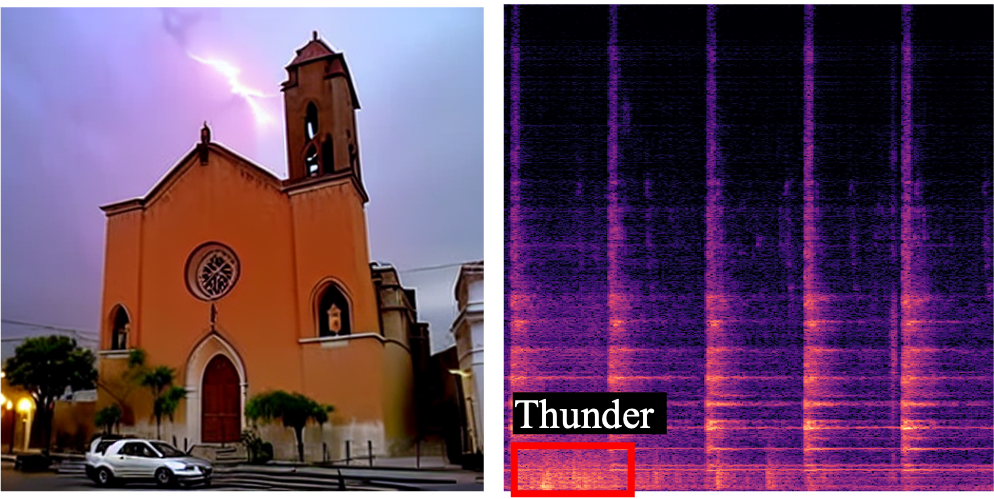
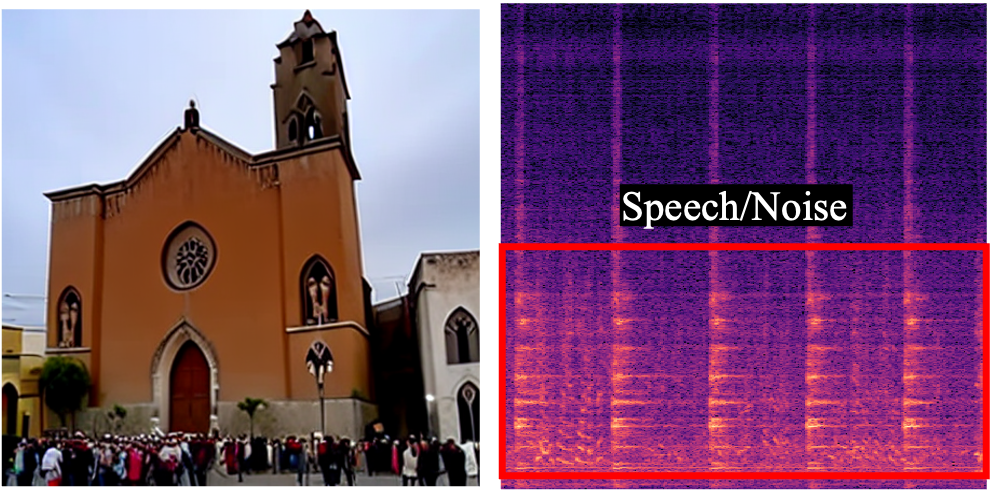
"A church bell is ringing"
(Input Audio-Visual Data)
"... with thunder roaring"
"... with people talking"
"A person is speaking"
(Input Audio-Visual Data)
"... by a crackling fireplace"
"A person is playing guitar"
(Input Audio-Visual Data)
"... surrounded by the crowd at a lively carnival"
"A person is speaking"
(Input Audio-Visual Data)
"... on road with a car passing by"
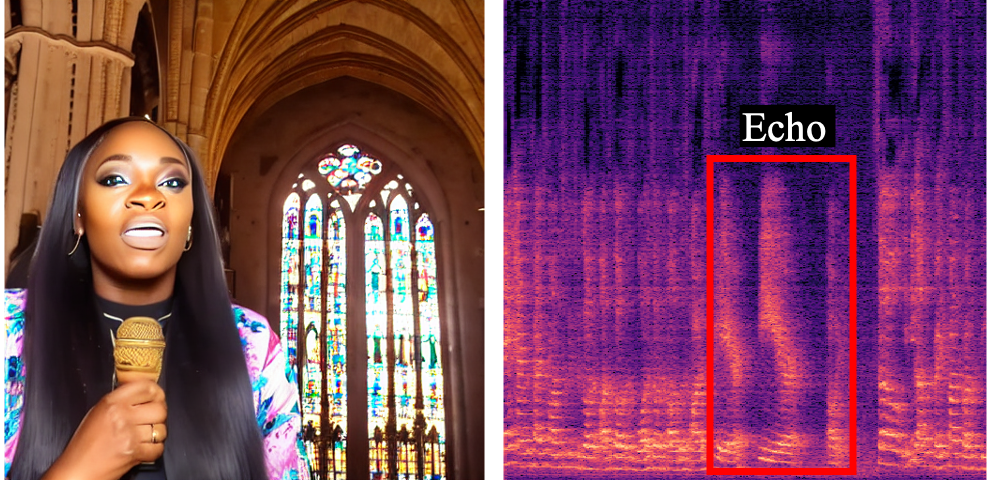
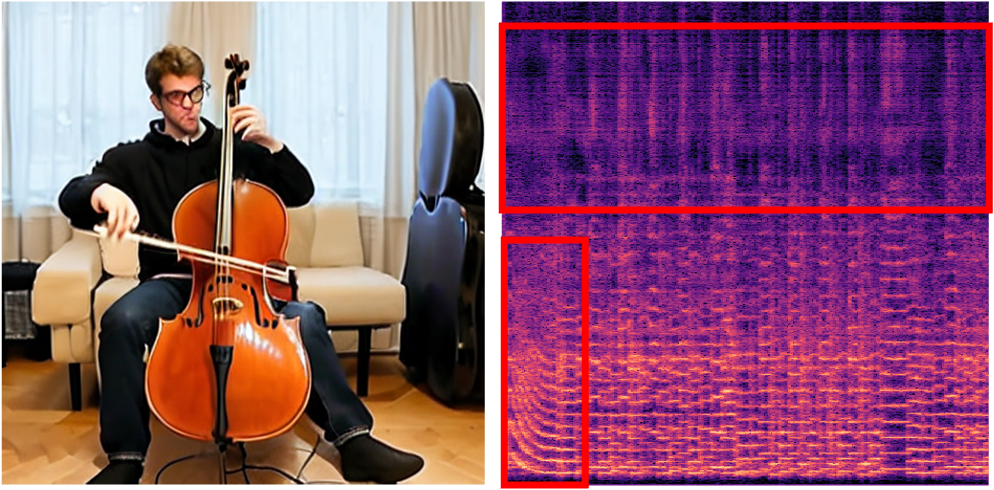
🌟 Room Acoustic Adjustment
We present the application of room acoustic adjustment enabled by our method. Here, we focus on adjusting the room environment of the user-provided data by text prompts. We highlight the audio effects with red boxes in the figures.
"A person is speaking"
(Input Audio-Visual Data)
"... in a large cathedral"
"A person is playing cello"
(Input Audio-Visual Data)
"... in a large cathedral"
🌟 Audio-Visual Composition
We present the application of audio-visual composition enabled by our method. Here, we focus on composing the learned sounding object with common objects. We highlight the new audio with red boxes in the figures.
"A person is playing violin"
(Input Audio-Visual Data)
"A dog is barking and playing violin"
"A child is laughing and playing violin"
"A person is playing ukulele"
(Input Audio-Visual Data)
"A dog is barking and playing ukulele"
"A child is laughing and playing ukulele on the grass"